
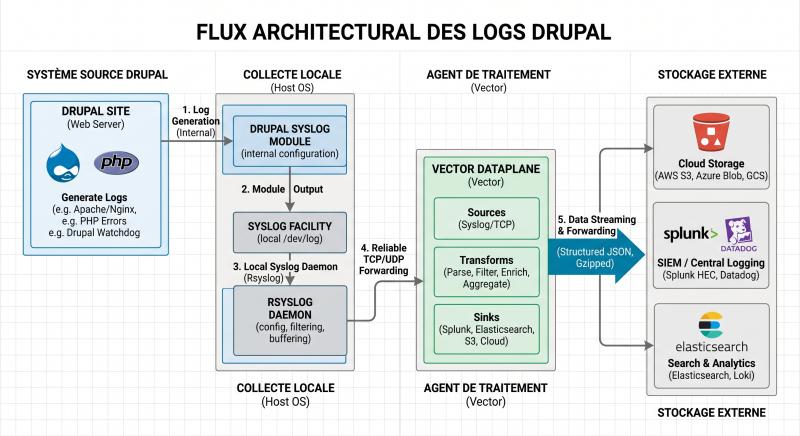
Dans les architectures web à fort trafic, la réactivité et la stabilité de l'infrastructure dépendent directement de la gestion des accès aux bases de données. Drupal, par défaut, utilise un système de journalisation interne qui écrit chaque événement système directement dans la base de données relationnelle. Si cette approche s'avère pratique en phase de développement, elle constitue une hérésie technique en production.
Ce guide détaille comment optimiser l'observabilité de vos serveurs de production en désactivant la journalisation en base de données, en exploitant le démon Rsyslog natif de Debian, et en construisant un pipeline d'acheminement moderne et sécurisé grâce à l'outil Vector.
Pourquoi bannir le module Database Logging (dblog) en production
Le module core Database Logging (historiquement connu sous le nom de watchdog) est activé par défaut sur la majorité des installations Drupal. Il stocke les avertissements PHP, les erreurs d'accès et les actions des utilisateurs dans la table SQL nommée watchdog.
L'impact critique sur les performances de la base de données MySQL
Chaque écriture de log via le module dblog est une opération synchrone. Lorsqu'un pic de trafic survient ou qu'une erreur PHP se répète en boucle, des milliers de requêtes INSERT saturent la base de données.
Voici les conséquences de cette surcharge sur votre serveur MySQL.
- Les requêtes d'écriture de logs entrent en concurrence directe avec les requêtes métiers critiques, comme la validation des paniers d'achat ou la recherche de contenus.
- La table
watchdogsubit une fragmentation intense en raison des écritures et des suppressions régulières effectuées par le cron de Drupal pour limiter sa taille. - Les verrous de lignes ou de tables (lock contention) se multiplient, augmentant considérablement le temps de réponse global de l'application.
Le risque d'indisponibilité et le coût d'I/O disque
L'écriture continue dans la base de données sollicite lourdement les entrées et sorties physiques sur le disque (I/O). Sur les instances de cloud public, la bande passante disque ou les IOPS sont souvent limités. Une saturation de ces ressources entraîne un ralentissement généralisé du serveur. Dans le pire des scénarios, si l'espace disque alloué à MySQL est totalement consommé par des logs volumineux, le service s'arrête brutalement, provoquant une interruption de service majeure.
Déporter les logs applicatifs : la configuration du module Syslog de Drupal
Pour préserver la base de données, la solution consiste à externaliser la journalisation. Drupal intègre un module nommé Syslog qui permet d'envoyer l'ensemble des messages de log au service de journalisation du système d'exploitation de manière asynchrone et extrêmement légère.
Activation et configuration du module Syslog dans Drupal
La première étape consiste à activer le module Syslog et à désactiver complètement le module Database Logging. Cette manipulation s'effectue rapidement en ligne de commande via l'outil Drush.
# Activation du module Syslog
drush pm:enable syslog -y
# Désactivation et désinstallation complète du module Database Logging
drush pm:uninstall dblog -y
Surcharge des paramètres via le fichier de configuration settings.php
Pour éviter que les configurations de journalisation ne soient modifiées accidentellement depuis l'interface d'administration de Drupal, il est fortement recommandé de figer ces variables directement dans le fichier sites/default/settings.php.
Le code suivant configure Drupal pour envoyer ses événements à la ressource système LOG_LOCAL0 en y associant un identifiant clair pour faciliter le filtrage ultérieur.
<?php
// Configuration stricte du module Syslog dans settings.php
$config['syslog.settings'] = [
'identity' => 'drupal_prod',
'facility' => '160', // Correspond à la ressource système LOG_LOCAL0
'format' => '!ip|!utype|!uid|!type|!message|!link',
];
Le choix de la ressource LOG_LOCAL0 permet d'isoler les logs applicatifs Drupal des logs du système Debian standard afin de simplifier leur traitement par Rsyslog.
Configuration de Rsyslog sous Debian : isoler les flux Drupal
Rsyslog est le démon de journalisation standard installé par défaut sur les distributions Debian. Nous allons l'utiliser pour intercepter les messages envoyés sur la ressource LOG_LOCAL0 et les rediriger vers un fichier spécifique, évitant ainsi de polluer le fichier système /var/log/syslog.
Définition d'une règle de filtrage pour les messages de type local
Sur votre serveur Debian, vous devez créer un fichier de configuration dédié à Drupal dans le répertoire de configuration de Rsyslog.
# Création du fichier de configuration Rsyslog pour Drupal
sudo nano /etc/rsyslog.d/drupal.conf
Ajoutez le contenu suivant dans ce fichier.
# Redirection des logs Drupal vers un fichier dédié
local0.* /var/log/drupal.log
# Empêcher les logs Drupal de s'écrire également dans /var/log/syslog
& stop
Pour appliquer cette nouvelle configuration, il est nécessaire de redémarrer le service Rsyslog.
# Vérification de la syntaxe de configuration de Rsyslog
sudo rsyslogd -N1
# Redémarrage du service si aucune erreur n'est détectée
sudo systemctl restart rsyslog
Rotation automatique des fichiers de logs pour préserver l'espace disque
Afin d'éviter que le nouveau fichier /var/log/drupal.log ne s'accumule indéfiniment et ne s'accapare tout l'espace disque, vous devez configurer l'utilitaire logrotate sous Debian.
# Création du fichier logrotate pour Drupal
sudo nano /etc/logrotate.d/drupal
Ajoutez les directives suivantes pour configurer une rotation quotidienne avec compression des archives.
/var/log/drupal.log {
daily
rotate 14
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
/usr/lib/rsyslog/rsyslog-rotate
endscript
}
Cette configuration conserve quatorze jours d'historique de logs compressés, ce qui s'avère amplement suffisant si les données sont expédiées vers une plateforme d'analyse centrale.
Construction de pipelines de logs modernes et sécurisés avec Vector
Vector est un outil de collecte, de transformation et d'acheminement de logs développé par Datadog en langage Rust. Il se distingue par sa rapidité, sa très faible empreinte mémoire et sa flexibilité par rapport à des outils plus anciens comme Logstash ou Fluentd.
Installation de Vector sur un serveur Debian
Pour installer Vector sur votre serveur Debian, vous devez ajouter le dépôt officiel et installer le paquet système.
# Installation des prérequis pour l'ajout de dépôts sécurisés
sudo apt update && sudo apt install -y curl gpg lsb-release
# Ajout de la clé de sécurité du dépôt Vector
curl -1sLf '[https://repositories.timber.io/public/vector/cfg/gpg/gpg.1B81E73C65D6A060.key](https://repositories.timber.io/public/vector/cfg/gpg/gpg.1B81E73C65D6A060.key)' | sudo gpg --dearmor -o /usr/share/keyrings/vector-archive-keyring.gpg
# Ajout du dépôt Vector dans les sources APT
echo "deb [signed-by=/usr/share/keyrings/vector-archive-keyring.gpg] [https://repositories.timber.io/public/vector/deb/debian](https://repositories.timber.io/public/vector/deb/debian) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/vector.list
# Mise à jour et installation de Vector
sudo apt update && sudo apt install -y vector
# Activation de Vector au démarrage du système
sudo systemctl enable vector
Configuration du pipeline : de la capture locale au masquage RGPD des données sensibles
Vector se configure via un fichier unique au format TOML situé dans /etc/vector/vector.toml. Nous allons configurer Vector pour écouter notre fichier /var/log/drupal.log, parser les messages, et appliquer une règle de sécurité stricte pour masquer les adresses e-mail conformément aux exigences du RGPD.
# Configuration globale de Vector
[sources.drupal_file]
type = "file"
include = ["/var/log/drupal.log"]
ignore_older_secs = 600
# Transformation et nettoyage des logs avec Vector Remap Language (VRL)
[transforms.parse_and_clean_drupal]
type = "remap"
inputs = ["drupal_file"]
source = """
# Analyse et parsing du format de log structuré
# Le format Drupal est défini par : IP|TypeUtilisateur|UID|Type|Message|Lien
.message_parts = split(string!(.message), "|")
if length(.message_parts) >= 6 {
.client_ip = .message_parts[0]
.user_type = .message_parts[1]
.user_uid = .message_parts[2]
.log_category = .message_parts[3]
.log_raw_message = .message_parts[4]
.log_link = .message_parts[5]
} else {
.log_raw_message = .message
}
# Masquage RGPD : remplacement des adresses e-mail par un filtre anonyme
# Cette expression régulière identifie et remplace les adresses de courriel
.log_raw_message = replace(.log_raw_message, r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}', "[EMAIL_MASQUE]")
# Suppression des champs temporaires superflus
del(.message_parts)
"""
Expédition des logs nettoyés vers une plateforme d'analyse externe
Une fois les logs collectés et purgés de toute information personnellement identifiable, Vector peut les acheminer vers de multiples destinations (OpenSearch, Elasticsearch, AWS S3, Datadog ou encore Grafana Loki).
Voici une configuration type pour expédier les logs enrichis vers un serveur Elasticsearch centralisé.
# Définition de la destination finale des logs
[sinks.elasticsearch_central]
type = "elasticsearch"
inputs = ["parse_and_clean_drupal"]
endpoint = "[https://elasticsearch-central.internal.net:9200](https://elasticsearch-central.internal.net:9200)"
index = "logs-drupal-prod-%Y-%m-%d"
mode = "bulk"
# Configuration de la sécurité de la connexion
auth.strategy = "basic"
auth.user = "vector-shipper"
auth.password = "un_mot_de_passe_hautement_securise"
Pour appliquer et démarrer le pipeline Vector, exécutez la commande suivante.
# Vérification de la configuration Vector
vector validate /etc/vector/vector.toml
# Redémarrage de Vector pour appliquer les modifications
sudo systemctl restart vector
Comparatif des méthodes de journalisation pour Drupal
Voici une synthèse des différences majeures entre la gestion des logs locale via base de données et l'architecture moderne déportée.
Utilisation de Database Logging (dblog)
- Impact sur les performances : très élevé en raison des requêtes d'écriture synchrones bloquantes sur la table de watchdog.
- Consommation des ressources de stockage : fragmentation rapide de la base de données MySQL et gonflement inutile de la taille des sauvegardes.
- Flexibilité d'analyse : faible car limitée à l'interface d'administration de Drupal qui devient inaccessible si le site est en panne.
- Conformité RGPD : complexe à automatiser car les logs bruts sont figés en base de données sans possibilité de filtrage dynamique à la volée.
Utilisation de Rsyslog associé à Vector
- Impact sur les performances : extrêmement faible grâce à l'utilisation d'appels système asynchrones non bloquants pour l'application PHP.
- Consommation des ressources de stockage : maîtrisée localement grâce à une rotation stricte avec logrotate et déportée sur un cluster optimisé pour la recherche.
- Flexibilité d'analyse : très élevée grâce aux capacités de filtrage, de tri et de visualisation de plateformes tierces d'observabilité.
- Conformité RGPD : excellente car Vector permet de filtrer, d'anonymiser et de masquer les données sensibles avant toute écriture physique ou réseau.
Foire aux questions (FAQ) sur l'observabilité des serveurs Drupal
Comment vérifier que Drupal envoie bien ses logs à Rsyslog ?
Vous pouvez générer une erreur ou un événement de connexion sur votre site Drupal, puis consulter en temps réel le fichier local sur votre serveur Debian via la commande suivante.
tail -f /var/log/drupal.logSi le fichier reste vide, assurez-vous que le module Syslog est correctement activé dans Drupal et que le service Rsyslog tourne sans erreur sur Debian.
Vector consomme-t-il beaucoup de ressources système par rapport à Logstash ?
Non, Vector est développé en Rust et a été conçu pour être extrêmement performant et économe en ressources système. Là où Logstash nécessite une machine virtuelle Java (JVM) consommant parfois plusieurs gigaoctets de mémoire vive, Vector fonctionne généralement avec seulement quelques dizaines de mégaoctets de RAM, ce qui en fait un agent idéal à déployer directement sur vos serveurs web de production.
Peut-on configurer Vector pour collecter également les logs d'Apache ou de Nginx ?
Oui, Vector est un outil de collecte universel. Il suffit de définir des sources additionnelles de type file pointant vers les chemins de vos journaux d'accès et d'erreurs de votre serveur web (par exemple /var/log/nginx/access.log), de les formater à l'aide de filtres VRL adaptés, et de les envoyer vers le même destinataire pour centraliser l'ensemble de votre observabilité.
Que se passe-t-il si la destination des logs (Elasticsearch) devient indisponible ?
Vector dispose d'un mécanisme de gestion de file d'attente (buffer). Si la destination finale est injoignable, Vector peut stocker temporairement les logs collectés en mémoire vive ou de manière persistante sur le disque local du serveur web. Dès que la connexion est rétablie, l'agent transmet l'ensemble des données en attente sans aucune perte d'informations.
